
Índice
Hace un més aproximadamente terminó el plazo de entrega de la práctica que voy a hablar hoy, lo que me permite hablaros de la misma.
En concreto, el ejercício consiste en realizar varias versiones de un algoritmo, para ver cómo varía la eficiencia del mismo en función de cómo se plantee el problema, obteniendo resultados sorprendentes en cuanto a tiempo de ejecución.
Se plantean dos ejercicios. El cálculo del número de bits a 1 que tiene un número (PopCount o Peso Hamming) usado para detectar y corregir errores.
El cálculo de la paridad impar de un número.
Empecemos con popCount:
/*
============================================================================
Name : Peso_popcount_C.c
Author : Alejandro Alcalde
Version :
Licence : GPL
Description : PopCount optimizations
============================================================================
*/
//gcc -Wall -m32 -O1 -fno-omit-frame-pointer pesopopcount_C.c -o pesopopcount_C
#define TEST 0
#define COPY_PASTE_CALC 0
#if ! TEST
#define NBITS 20
#define SIZE (1<<NBITS) //Tamaño suficiente para tiempo apreciable
unsigned lista[SIZE];
#define RESULT 10485760
#else
#define SIZE 4
unsigned lista[SIZE] = {0x80000000, 0x00100000, 0x00000800, 0x00000001};
#define RESULT 4
#endif
#include <stdio.h> // para printf()
#include <stdlib.h> // para exit()
#include <sys/time.h> // para gettimeofday(), struct timeval
#define WSIZE 8*sizeof(int)
int resultado = 0;
int popcount1(unsigned* array, int len) {
int i, k;
int result = 0;
for (k = 0; k < len; k++)
for (i = 0; i < WSIZE; i++) {
unsigned mask = 1 << i;
result += (array[k] & mask) != 0;
}
return result;
}
int popcount2(unsigned* array, int len) {
int result = 0;
int i;
unsigned x;
for (i = 0; i < len; i++) {
x = array[i];
while (x) {
result += x & 0x1;
x >>= 1;
}
}
return result;
}
int popcount3(unsigned* array, int len) {
int result = 0;
int i;
unsigned x;
for (i = 0; i < len; i++) {
x = array[i];
asm("n"
"ini3: nt"
"shr $0x1, %[x] nt" //Desplazar afecta a CF ZF
"adc $0x0, %[r] nt"
"test %[x], %[x] nt"
"jnz ini3 "
: [r] "+r" (result)// e/s: inicialmente 0, salida valor final
: [x] "r" (x) );
}
return result;
}
/*
* Versión C de CS:APP
*/
int popcount4(unsigned* array, int len) {
int i, k;
int result = 0;
for (i = 0; i < len; i++) {
int val = 0;
unsigned x = array[i];
for (k = 0; k < 8; k++) {
val += x & 0x01010101; //00000001 00000001 00000001 00000001
x >>= 1;
}
//val += (val >> 32);
val += (val >> 16);
val += (val >> 8);
result += (val & 0xff);
}
return result;
}
/**
* Versión SSSE3 (pshufb) web http:/wm.ite.pl/articles/sse-popcount.html
*/
int popcount5(unsigned* array, int len) {
int i;
int val, result = 0;
int SSE_mask[] = { 0x0f0f0f0f, 0x0f0f0f0f, 0x0f0f0f0f, 0x0f0f0f0f };
int SSE_LUTb[] = { 0x02010100, 0x03020201, 0x03020201, 0x04030302 };
if (len & 0x3)
printf("leyendo 128b pero len no múltiplo de 4?n");
for (i = 0; i < len; i += 4) {
asm("movdqu %[x], %%xmm0 nt"
"movdqa %%xmm0, %%xmm1 nt" // dos copias de x
"movdqu %[m], %%xmm6 nt"// máscara
"psrlw $4, %%xmm1 nt"
"pand %%xmm6, %%xmm0 nt"//; xmm0 – nibbles inferiores
"pand %%xmm6, %%xmm1 nt"//; xmm1 – nibbles superiores
"movdqu %[l], %%xmm2 nt"//; ...como pshufb sobrescribe LUT
"movdqa %%xmm2, %%xmm3 nt"//; ...queremos 2 copias
"pshufb %%xmm0, %%xmm2 nt"//; xmm2 = vector popcount inferiores
"pshufb %%xmm1, %%xmm3 nt"//; xmm3 = vector popcount superiores
"paddb %%xmm2, %%xmm3 nt"//; xmm3 - vector popcount bytes
"pxor %%xmm0, %%xmm0 nt"//; xmm0 = 0,0,0,0
"psadbw %%xmm0, %%xmm3 nt"//;xmm3 = [pcnt bytes0..7|pcnt bytes8..15]
"movhlps %%xmm3, %%xmm0 nt"//;xmm3 = [ 0 |pcnt bytes0..7 ]
"paddd %%xmm3, %%xmm0 nt"//;xmm0 = [ no usado |pcnt bytes0..15]
"movd %%xmm0, %[val] nt"
: [val]"=r" (val)
: [x] "m" (array[i]),
[m] "m" (SSE_mask[0]),
[l] "m" (SSE_LUTb[0])
);
result += val;
}
return result;
}
/**
* Versión SSE4.2 (popcount)
*/
int popcount6(unsigned* array, int len) {
int i;
unsigned x;
int val, result = 0;
for (i = 0; i < len; i++) {
x = array[i];
asm("popcnt %[x], %[val] nt"
: [val]"=r"(val)
: [x] "r" (x)
);
result += val;
}
return result;
}
int popcount7(unsigned* array, int len) {
int i;
unsigned x1, x2;
int val, result = 0;
if (len & 0x1)
printf("Leer 64b y len impar?n");
for (i = 0; i < len; i += 2) {
x1 = array[i];
x2 = array[i + 1];
asm("popcnt %[x1], %[val] nt"
"popcnt %[x2], %%edi nt"
"add %%edi, %[val] nt"
: [val]"=r"(val)
: [x1] "r" (x1),
[x2] "r" (x2)
: "edi"
);
result += val;
}
return result;
}
void crono(int (*func)(), char* msg) {
struct timeval tv1, tv2; // gettimeofday() secs-usecs
long tv_usecs; // y sus cuentas
gettimeofday(&tv1, NULL);
resultado = func(lista, SIZE);
gettimeofday(&tv2, NULL);
tv_usecs = (tv2.tv_sec - tv1.tv_sec) * 1E6 + (tv2.tv_usec - tv1.tv_usec);
#if ! COPY_PASTE_CALC
printf("resultado = %dt", resultado);
printf("%s:%9ld usn", msg, tv_usecs);
#else
printf("%9ld usn", tv_usecs);
#endif
}
int main() {
#if ! TEST
int i; // inicializar array
for (i = 0; i < SIZE; i++) // se queda en cache
lista[i] = i;
#endif
crono(popcount1, "popcount1 ( en lenguaje C for )");
crono(popcount2, "popcount2 ( en lenguaje C whi )");
crono(popcount3, "popcount3 ( Ahorrando máscara )");
crono(popcount4, "popcount4 (Sumando bytes completos)");
crono(popcount5, "popcount5 ( SSSE3 )");
crono(popcount6, "popcount6 ( SSSE4.2 )");
crono(popcount7, "popcount7 ( SSSE4.2 64b )");
exit(0);
}
En este caso se han escrito siete formas de hacer el cálculo del peso Hamming o popcount, con el objetivo de comprobar cual de ellas es más rápida haciendo cálculos. Concretamente, la función popcount6() solo es posible ejecutarla en procesadores que tengan la instrucción popcnt en su repertorio.
Para evaluar correctamente qué función es más eficiente, procedemos a ejecutar el programa varias veces seguidas con watch, comando que ejecuta el programa que se le pasa como parámetro cada 0.1 segundos (-n .1):
$ watch -dc -n .1 ./popcount
resultado = 10485760 popcount1 ( en lenguaje C for ): 59482 us
resultado = 10485760 popcount2 ( en lenguaje C whi ): 19456 us
resultado = 10485760 popcount3 ( Ahorrando máscara ): 26806 us
resultado = 10485760 popcount4 (Sumando bytes completos): 10579 us
resultado = 10485760 popcount5 ( SSSE3 ): 968 us
resultado = 10485760 popcount6 ( SSSE4.2 ): 1046 us
resultado = 10485760 popcount7 ( SSSE4.2 64b ): 825 us
Como se aprecia, las versiones 5 y 7 parecen ser las más rápidas, y la primera notablemente más lenta. Veamos las razones de estas mejoras (Extraidas del guión de prática.)
En la versión 3 (popcount3), sustituimos el bucle while de la versión dos por unas pocas líneas ensamblador que incluyen la instrucción ADC (suma con acarreo). La instrucción SHR desplaza bits hacia la derecha, si el último bit desplazado fue un 1, éste se almacena en el flag de acarreo (CF), con lo cual podemos sumarlo y ahorramos aplicar la máscara. En principio, debería suponer alguna mejora.
La cuarta versión (popcount4) aplica sucesivamente la máscara a cada elemento, para acumular los bits de cada byte en una variable val y suma en árbol los 4 Bytes.
Una quinta versión implementa instrucciones SSSE3.
Por último, las versiones seis y siete hacen uso de la instrucción popcnt, que realiza el recuento de los bits, aunque debe ser necesario que el procesador la tenga implementada.
Comprobando qué implementación es más eficiente
A fin de conseguir unos resultados estadísticamente aceptables, el programa se ejecuta 11 veces como se menciona arriba, para los tres niveles de optimización que ofrece el compilador. Las opciones usadas por gcc han sido las siguientes:
gcc -O<n> -Wall -m32 -fno-omit-frame-pointer pesoHamming_C.c -o pesoHamming_C
Donde <n> es el nivel de optimización.
Introdujimos los resultados de los tiempos de ejecución en una hoja de cálculo para crear una tabla comparativa con gráficos:
{kind=link}
Y creamos las gráficas:
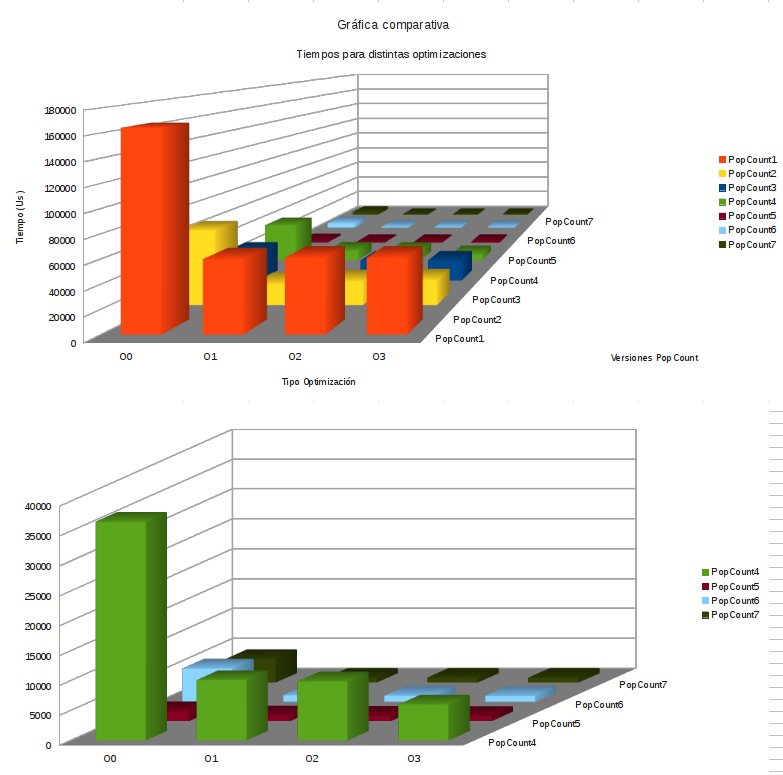{kind=link}
La diferencia de resultados es notoria, se aprecia que la mejor optimización se consigue con O1 u O2, siendo la versión popcount7 la más eficiente.
Moraleja
Como queda demostrado, en función de cómo se plantee la resolución de un problema, pueden existir diferencias abismales en términos de eficiencia y tiempo de ejecución, el compilador hace un buen trabajo optimizando el código, pero también es muy importante reflexionar sobre la implementación del código. Se ha conseguido pasar de una versión que tomó 59.921 us (popcount1 con -O1) a otra que tardó 884 us (popcount7 con -O1)
El caso del cálculo de la paridad es similar, en esta caso simplemente proporciono el código para los curiosos:
/*
============================================================================
Name : Paridad.c
Author : Alejandro
Version :
============================================================================
*/
/*gcc -m32 -O1 -fno-omit-frame-pointer pesopopcount_C.c -o pesopopcount_C*/
/*gcc -O0 -g -Wall -Wextra -Wpedantic -m32 -fno-omit-frame-pointer*/
#define TEST 0
#define COPY_PASTE_CALC 0
#if ! TEST
#define NBITS 20
#define SIZE (1<<NBITS) /*Tamaño suficiente para tiempo apreciable*/
unsigned lista[SIZE];
#define RESULT 10485760
#else
#define SIZE 8
//unsigned lista[SIZE] = {0x80000000, 0x00100000, 0x00000800, 0x00000001};
//unsigned lista[SIZE] = {0x7fffffff, 0xffefffff, 0xfffff7ff, 0xfffffffe, 0x01000024,
// 0x00356700, 0x8900ac00, 0x00bd00ef};
#endif
#include <stdio.h> // para printf()
#include <stdlib.h> // para exit()
#include <sys/time.h> // para gettimeofday(), struct timeval
#define WSIZE 8*sizeof(int)
//#define SIZE (1<<20) // tamaño suficiente para tiempo apreciable
//unsigned lista[SIZE]; // = { 0x01010101 }; // 0x00000003, 0x00000003};
int resultado = 0;
int paridad1(unsigned* array, int len) {
unsigned i, j;
int paridad;
unsigned entero;
int result = 0;
for (i = 0; i < len; i++) {
paridad = 0;
entero = array[i];
for (j = 0; j < WSIZE; j++) {
paridad ^= (entero & 1);
entero >>= 1;
}
result += paridad & 0x01;
}
return result;
}
int paridad2(unsigned* array, int len) {
int i;
int paridad;
unsigned entero;
int result = 0;
for (i = 0; i < len; i++) {
paridad = 0;
entero = array[i];
while (entero) {
paridad ^= (entero & 1);
entero >>= 1;
}
result += paridad & 0x1;
}
return result;
}
/*
* Versión C de CS:APP Ejercicio 3.22
*/
int paridad3(unsigned* array, int len) {
int val = 0;
int i;
unsigned x;
int result = 0;
for (i = 0; i < len; i++) {
x = array[i];
while (x) {
val ^= x;
x >>= 1;
}
result += val & 0x1;
}
return result;
}
/*
* Versión C de CS:APP Ejercicio 3.22 (Traduciendo while)
*/
int paridad4(unsigned* array, int len) {
int val;
int i;
unsigned x;
int result = 0;
for (i = 0; i < len; i++) {
x = array[i];
val = 0;
asm(
"ini3: nt"
"xor %[x], %[v] nt"
"shr $1, %[x] nt"
"test %[x], %[x] nt"
"jnz ini3 nt"
: [v]"+r"(val) // e/s: inicialemnte 0, salida valor final
: [x]"r"(x)// entrada: valor del elemento
);
result += val & 0x1;
}
return result;
}
/**
* Sumando en árbol
*/
int paridad5(unsigned* array, int len) {
int i, k;
int result = 0;
unsigned x;
for (i = 0; i < len; i++) {
x = array[i];
for (k = 16; k == 1; k /= 2)
x ^= x >> k;
result += (x & 0x01);
}
return result;
}
int paridad6(unsigned* array, int len) {
int j;
unsigned entero = 0;
int resultado = 0;
for (j = 0; j < len; j++) { //Cuando acabe de recorrer el vector se saldrá del bucle
entero = array[j]; //Cargo en entero el siguiente numero de la lista
asm(
"mov %[x], %%edx nt"
"shr $16, %%edx nt"
"xor %[x], %%edx nt"
"xor %%dh, %%dl nt"
"setpo %%dl nt"
"movzx %%dl, %[x] nt"
: [x] "+r" (entero) // input
:
: "edx"//Clobber
);
resultado += entero;
}
return resultado;
}
void crono(int (*func)(), char* msg) {
struct timeval tv1, tv2; // gettimeofday() secs-usecs
long tv_usecs; // y sus cuentas
gettimeofday(&tv1, NULL);
resultado = func(lista, SIZE);
gettimeofday(&tv2, NULL);
tv_usecs = (tv2.tv_sec - tv1.tv_sec) * 1E6 + (tv2.tv_usec - tv1.tv_usec);
#if ! COPY_PASTE_CALC
printf("resultado = %dt", resultado);
printf("%s:%9ld usn", msg, tv_usecs);
#else
printf("%9ld usn", tv_usecs);
#endif
}
int main() {
#if ! TEST
int i; // inicializar array
for (i = 0; i < SIZE; i++) // se queda en cache
lista[i] = i;
#endif
crono(paridad1, "Paridad1 ( en lenguaje C for )");
crono(paridad2, "Paridad2 ( en lenguaje C whi )");
crono(paridad3, "Paridad3 (Ejemplo CS:APP Ej: 3.22)");
crono(paridad4, "Paridad4 (Traducción bucle While )");
crono(paridad5, "Paridad5 ( Suma en árbol )");
crono(paridad6, "Paridad6 (Bucle interno con setpe)");
exit(0);
}
Descargar guión
Para todo aquel interesado, tengo permiso para distribuir el guión bajo licencia creative commons desarrollado por los profesores Francisco Javier Fernández Baldomero y Mancia Anguita López del departamento de Arquitectura y Tecnología de Computadores de la Universidad de Granada.
¿Has visto algún error?: Por favor, ayúdame a corregirlo contactando conmigo o comentando abajo.